
티스토리 뷰
단어 임베딩에 대해서 알아봅시다!
WHAT?
=> 단어간의 유사성을 나타내기 위하여 단어를 부동 소수점 값의 조밀한 벡터로 나타내는데 이를 임베딩이라고 합니다.
WHY?
유사한 단어가 유사한 인코딩을 가지는 효율적이고 조밀한 표현을 사용하는 방법을 제공함으로써 기존의 단어 인코딩값에 대한 문제점을 해결하기 위해서 사용됩니다.
HOW?
임베딩에 대한 값을 수동으로 저장하는 기존의 encoding방식과 달리 embedding의 경우, 모델이 학습하며 단어간의 유사성을 벡터화시켜서 실수값의 조합으로 표현합니다. 벡터의 길이는 사용자가 지정하는 것이 맞지만 그 벡터안의 실수를 학습을 통해서 조정시켜가는 것입니다.
https://www.tensorflow.org/text/guide/word_embeddings?hl=ko
단어 임베딩 | Text | TensorFlow
도움말 Kaggle에 TensorFlow과 그레이트 배리어 리프 (Great Barrier Reef)를 보호하기 도전에 참여 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English 단어 임베딩 이 자습서에는 단어 임
www.tensorflow.org
embedding_layer = tf.keras.layers.Embedding(1000, 5)학습을 진행하기 위한 모델을 compile할때, 단어가 정의된 사전의 단어 데이터가 1000개라면 Embedding의 첫번째 인자로 1000을 지정합니다. 이후, 사용자가 지정할 수 있는 벡터의 크기를 넣습니다. 그렇다면 하나의 단어는 Embedding되어 다음과 같이 벡터화 되어 저장되어 유사성 정도를 파악하기 쉬우며 모델을 학습하기에 적합한 모델로 탄생합니다.
<<CAT>>
| 1.2 | -0.1 | 4.3 | 3.2 | 2,4 |
위의 숫자는 그저 예시를 들기 위해서 임의로 지정한 숫자입니다.
칸이 5개인 이유는 벡터의 SIZE를 5로 지정하였기 때문입니다. CAT의 벡터가 다음과 같습니다. 다음과 같은 실수로 저장이 되며 다른 단어들의 벡터를 따져봐서 형태가 비슷하다면 이것은 유사성이 높다고 볼 수 있습니다.
이때, NNLM가 WORD2VEC이 존재합니다.
1. NNLM => 활성화 함수가 있는 은닉층이 존재함.
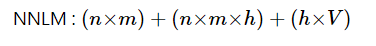
2. WORD2VEC => 은닉층을 제거. => 투사층 다음으로 바로 출력층이 연결됨
+[네커티브 샘플링을 사용해서 NNLM과의 학습속도적인 측면에서 강점을 보임]
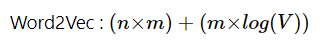
단어 임베딩의 예로 Word2Vec이 있는데 Word2Vec은 말그대로 word를 위에서 설명했듯이 vector화 시키는 것을 의미한다.
이때 두가지 방법이 존재하는데 단어를 주변에 따라서 중간 단어를 예측하는 모델(순서가 중요하지 않음), 스킵 그램 모델(현재 단어가 주어지면 그 단어의 이웃을 예측하는 방법)이 있다.
1. CBOW
window size만큼 중심 데이터에서 양옆의 데이터(양옆의 단어)를 가져와서 단순한 "투시층"을 거쳐서 중심 단어를 선택하는 방법이다.
만약 vector의 크기가 7로 단어 사전에 7종류의 단어가 존재하고 사용자가 지정한 Embedding model의 vector size가 5라면? 그리고 window size를 2라고 해봅시다.
그렇다면 양쪽으로 모두 2개의 데이터가 존재한다면 2개를 가져와서 총 4개를 가져오게 됩니다.
이후, 해당 단어들이 7개의 단어중 해당하는 값으로 one-hot-encoding이 되어있는데 그 값 encoding된 벡터들이 총 4개가 존재하게 되는데 이를 활용해서 model에 적용시켜서 model을 최적화시키며 가운데의 목표 단어를(one-hot-encoding형태로 encoding된 단어)를 알아냅니다,
그 과정에 대해서 알아보기 위해서
https://wikidocs.net/22660
02) 워드투벡터(Word2Vec)
앞서 원-핫 인코딩 챕터에서 원-핫 벡터는 단어 간 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 간 유사도를 반영할 수 있도록 단어의 의미를 ...
wikidocs.net
를 참고했습니다.
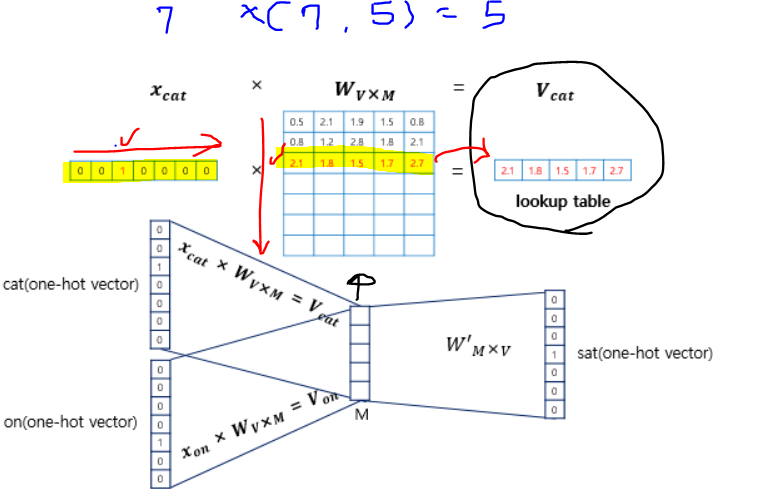
W와 one-hot-encoding으로 읽은 데이터들을 곱해서 생긴 결과들은 투시층에서 평균을 구하게 됩니다.
이때, 소프트맥스 함수를 다중분류에서 확률값을 통해서 분류를 하기 위해서 사용한 것처럼 벡터에 소프트맥스함수를 취합니다. 그렇다면 가장큰 하나의 확률이 나오게 될 것이고 그 값을 가지고 있는 벡터의 부분이 1이 되며 그 단어가 다시 one-hot encoding된 형태로 나오게 됩니다. 이때, 정확한지 아닌지 손실함수를 cross-entropy를 사용합니다.
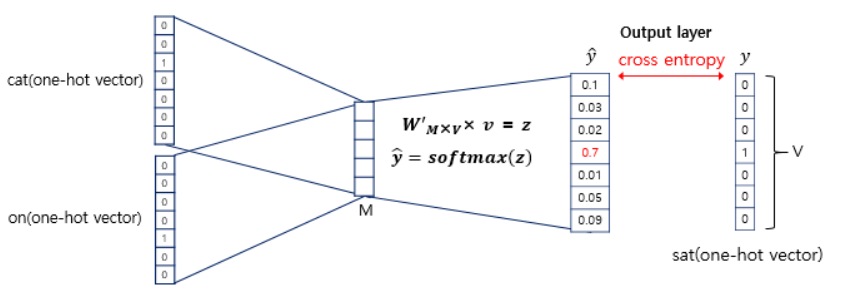
소프트맥스 함수를 활용해서 y^을 뽑았고 그 가장 큰 값이 1이 되어 one-hot-encoding되어 word인 sat을 예측합니다. 이때, 가장 큰 값이 1에 가까울수록 loss가 작은 것이므로 오차가 줄어들어 정확한 단어를 예측한 것이 됩니다. 오차를 줄이기 위해서 역전파과정을 시도하고 이때, cross-entropy를 활용해서 loss를 줄이는 과정을 반복하며 W, W'에을 학습시킵니다.
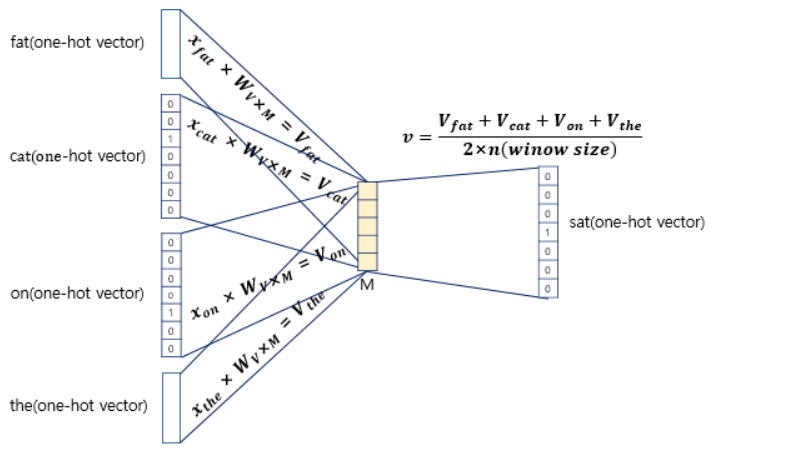
2. Skip-diagram(성능이 더 좋다고 알려짐)
하나의 단어에서 각 양옆으로 window size만큼의 단어들을 예측하는 모델입니다. 따라서 BOW와 달리 단어들을 W를 곱한 이후에 평균을 구하는 과정이 없습니다.
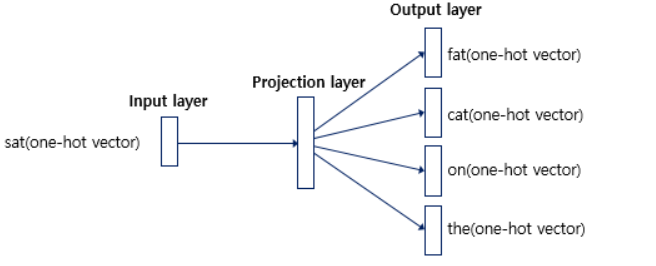
word2vec에서 긍정, 부정으로 나눠서 현재 집중 중인 데이터가 중심단어의 근처에 있는 관계가 맞는지 확인하여 근처에있지 않다면 부정으로 '0'으로 판단하여 의미를 두지 않고 근처에 있는 단어라면 '1'을 넣어 의미를 둡니다. 이때, 해당 중심 데이터에 대한 Embedding layer하나를 룩업하고 그 주변 단어에 대한 layer를 통해 look up해서 총 2개의 layer를 통해서 중심단어는 두번째 layer의 look up 된 부분만으로 에측값을 내서 레이블을 찾아냅니다. 레이블과의 오차로부터 역전파해서 임베딩 layer를 update하는 방식으로 embedding할 수 있습니다.
https://woochan-autobiography.tistory.com/564
Negative Sampling
1. 네거티브 샘플링(Negative Sampling) Word2Vec의 출력층에서는 소프트맥스 함수를 지난 단어 집합 크기의 벡터와 실제값인 원-핫 벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에
woochan-autobiography.tistory.com
를 참고
- Total
- Today
- Yesterday
- 13886
- 영화 리뷰 긍정 부정 분류
- 코딩월드뉴스
- 기사작성 대외활동
- DRF 회원관리
- 소프트웨어공학설계
- LAMBDA
- mm1queue
- CREATE ASSERTION
- 시뮬레이션 c
- 백준 15650 파이썬
- 백트래킹(1)
- 10866 백준
- c++덱
- 딥러닝입문
- 기본 텍스트 분류
- CSMA/CD란?
- 백준 10866
- 모듈 사용법
- 파이썬 알아두면 유용
- 백준 11053 파이썬
- 핀테크 트렌드
- 백준 4963
- stack 컨테이너
- 11053 백준
- 4963 섬의개수
- 백준 숫자놀이
- 온라인프로필 만들기
- 효율적인방법찾기
- 스택 파이썬
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |